
什么是 Zookeeper
Zookeeper 是一个分布式开源框架,提供了协调分布式应用的基本服务,它向外部应用暴露一组通用服务——分布式同步(Distributed Synchronization)、命名服务(Naming Service)、集群维护(Group Maintenance)等,简化分布式应用协调及其管理的难度,提供高性能的分布式服务。ZooKeeper本身可以以单机模式安装运行,不过它的长处在于通过分布式 ZooKeeper 集群(一个 Leader,多个 Follower),基于一定的策略来保证 ZooKeeper 集群的稳定性和可用性,从而实现分布式应用的可靠性。
- Zookeeper 是为别的分布式程序服务的
- Zookeeper 本身就是一个分布式程序(只要有半数以上节点存活,zk 就能正常服务)
- Zookeeper 所提供的服务涵盖:主从协调、服务器节点动态上下线、统一配置管理、分布式共享锁、统> 一名称服务等
- 虽然说可以提供各种服务,但是 zookeeper 在底层其实只提供了两个功能:管理(存储,读取)用户程序提交的数据(类似 namenode 中存放的 metadata); 并为用户程序提供数据节点监听服务;
Zookeeper 集群机制
Zookeeper 集群的角色: Leader 和 follower
只要集群中有半数以上节点存活,集群就能提供服务
Zookeeper 特性
- Zookeeper:一个 leader,多个 follower 组成的集群
- 全局数据一致:每个 server 保存一份相同的数据副本,client 无论连接到哪个 server,数据都是一致的
- 分布式读写,更新请求转发,由 leader 实施
- 更新请求顺序进行,来自同一个 client 的更新请求按其发送顺序依次执行
- 数据更新原子性,一次数据更新要么成功,要么失败
- 实时性,在一定时间范围内,client 能读到最新数据
Zookeeper 数据结构
ZooKeeper 提供的名称空间非常类似于标准文件系统。名称是由斜线(/)分隔的一系列路径元素。ZooKeeper 名称空间中的每个节点都由一个路径标识。
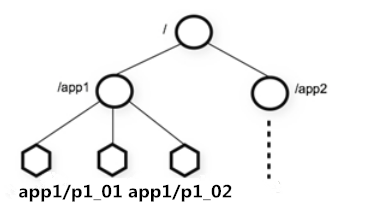
树是由节点所组成,zookeeper 的数据存储也同样是基于节点,这个节点叫做 Znode.但是,不同于树的节点,Znode 的引用方式是路径引用,类似于文件路径:/app1/p_1。
这样的层级结构,让每一个Znode节点拥有唯一的路径,就像命名空间一样对不同信息作出清晰的隔离。
ZooKeeper 中节点和临时节点
ZooKeeper 的节点是通过像树一样的结构来进行维护的,并且每一个节点通过路径来标示以及访问。除此之外,每一个节点还拥有自身的一些信息,包括:数据、数据长度、创建时间、修改时间等等。从这样一类既含有数据,又作为路径表标示的节点的特点中,可以看出,ZooKeeper 的节点既可以被看做是一个文件,又可以被看做是一个目录,它同时具有二者的特点。
具体地说,Znode 维护着数据、ACL(access control list,访问控制列表)、时间戳等交换版本号等数据结构,它通过对这些数据的管理来让缓存生效并且令协调更新。每当 Znode 中的数据更新后它所维护的版本号将增加,这非常类似于数据库中计数器时间戳的操作方式。
另外 Znode 还具有原子性操作的特点:命名空间中,每一个 Znode 的数据将被原子地读写。读操作将读取与 Znode 相关的所有数据,写操作将替换掉所有的数据。除此之外,每一个节点都有一个访问控制列表,这个访问控制列表规定了用户操作的权限。
ZooKeeper 中同样存在临时节点。这些节点与 session 同时存在,当 session 生命周期结束,这些临时节点也将被删除。临时节点在某些场合也发挥着非常重要的作用。
Zookeeper 应用场景
- 数据发布与订阅(配置中心)
- 负载均衡
- 命名服务(Naming Service)
- 分布式通知/协调
- 集群管理与 Master 选举
- 分布式锁
- 分布式事务
更多教程可以参考官方文档,大家可以去Apache ZooKeeper 官方文档。
持续更新中…
